%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Speech Recognition
Speechly
Speechly is a tool that converts your speech into structured emails, allowing you to effortlessly obtain clear and readable information in up to 100 languages.
Email Assistant
38.1K

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
39.2K

Amazon Nova Sonic
Amazon Nova Sonic is a cutting-edge foundational model that integrates speech understanding and generation, enhancing the natural fluency of human-computer dialogue. This model overcomes the complexities of traditional voice applications, achieving a deeper level of communication understanding through a unified architecture. It is suitable for AI applications across multiple industries and holds significant commercial value. As AI technology continues to develop, Nova Sonic will provide customers with better voice interaction experiences and improved service efficiency.
Speech Recognition
39.5K
Chinese Picks
Inkr
Inkr transcription is an online tool focusing on audio and video transcription. Using advanced speech recognition technology, it quickly converts audio or video files into text. Its main advantages include fast transcription speed, high accuracy, and support for multiple languages and file formats. Positioned as a high-efficiency office and learning aid, it aims to help users save time and effort, improving work efficiency. Inkr transcription offers a free trial version, allowing users to experience its core functions. The paid version provides more advanced features and large file support to meet the needs of different users.
Speech-to-text
52.2K
Durt
DuRT is a speech recognition and translation tool focusing on macOS. It uses local AI models and system services to achieve real-time speech recognition and translation, supporting multiple speech recognition methods to improve accuracy and language support. The product displays results in a floating window for easy access during use. Its main advantages include high accuracy, privacy protection (no user information is collected), and a convenient user experience. DuRT is positioned as a highly efficient productivity tool, designed to help users communicate and work more efficiently in multilingual environments. The product is currently available on the Mac App Store; pricing is not explicitly mentioned on the page.
Speech Recognition
49.4K
Elevenlabs Scribe
Scribe is a high-accuracy speech-to-text model developed by ElevenLabs, designed to handle the unpredictability of real-world audio. It supports 99 languages and provides features such as word-level timestamps, speaker diarization, and audio event labeling. Scribe demonstrates superior performance on the FLEURS and Common Voice benchmarks, surpassing leading models like Gemini 2.0 Flash, Whisper Large V3, and Deepgram Nova-3. It significantly reduces error rates for traditionally underserved languages (such as Serbian, Cantonese, and Malayalam), where error rates often exceed 40% in competing models. Scribe offers an API for developer integration and will launch a low-latency version to support real-time applications.
Speech Recognition
61.3K
Fresh Picks
Phi 4 Multimodal Instruct
Phi-4-multimodal-instruct is a multimodal foundational model developed by Microsoft, supporting text, image, and audio inputs to generate text outputs. Built upon the research and datasets of Phi-3.5 and Phi-4.0, the model has undergone supervised fine-tuning, direct preference optimization, and reinforcement learning from human feedback to improve instruction following and safety. It supports multilingual text, image, and audio inputs, features a 128K context length, and is applicable to various multimodal tasks such as speech recognition, speech translation, and visual question answering. The model demonstrates significant improvements in multimodal capabilities, particularly excelling in speech and vision tasks. It provides developers with powerful multimodal processing capabilities for building a wide range of multimodal applications.
AI Model
53.3K

Fireredasr AED L
FireRedASR-AED-L is an open-source, industrial-grade automatic speech recognition model designed to meet the needs for high efficiency and performance in speech recognition. This model utilizes an attention-based encoder-decoder architecture and supports multiple languages including Mandarin, Chinese dialects, and English. It achieved new record levels in public Mandarin speech recognition benchmarks and has shown exceptional performance in singing lyric recognition. Key advantages of the model include high performance, low latency, and broad applicability across various speech interaction scenarios. Its open-source feature allows developers the freedom to use and modify the code, further advancing the development of speech recognition technology.
Speech Recognition
56.9K
Fireredasr
FireRedASR is an open-source industrial-grade Mandarin automatic speech recognition model, utilizing an Encoder-Decoder and LLM integrated architecture. It includes two variants: FireRedASR-LLM and FireRedASR-AED, designed for high-performance and efficient needs respectively. The model excels in Mandarin benchmarking tests and also performs well in recognizing dialects and English speech. It is suitable for industrial applications requiring efficient speech-to-text conversion, such as smart assistants and video subtitle generation. The open-source model is easy for developers to integrate and optimize.
Speech Recognition
56.0K
Bulletpen
Bulletpen is an innovative AI writing application designed to help users convert their verbal expressions into high-quality written text. Utilizing speech recognition and natural language processing technologies, it optimizes and polishes users' spoken content, resulting in clear structure and fluent language in written form. The main advantage of this product is its ability to significantly enhance writing efficiency, particularly for those who find writing challenging or lack inspiration. Developed by 17-year-old high school student Rexan Wong, Bulletpen aims to provide a user-friendly writing assistance tool for students, writers, and content creators. It offers both free and paid plans to cater to different user needs.
Writing Assistant
50.5K
Realtimestt
RealtimeSTT is an open-source speech recognition model capable of converting spoken language into text in real time. It employs advanced voice activity detection technology to automatically detect the start and end of speech without manual intervention. Additionally, it supports wake word activation, allowing users to initiate speech recognition by saying specific wake words. The model is characterized by low latency and high efficiency, making it suitable for real-time transcription applications such as voice assistants and meeting notes. It is developed in Python, easy to integrate and use, and is open-source on GitHub, with an active community that continuously provides updates and improvements.
Speech Recognition
104.1K
Chinese Picks
Tongyi Browser Plugin
Tongyi is a browser plugin that integrates speech recognition, real-time subtitle translation, and intelligent summarization features, aimed at enhancing users' efficiency in scenarios like online courses, binge-watching shows, and virtual meetings. Utilizing AI technology, it assists users in quickly recording, transcribing, translating, and summarizing web content, making it particularly suitable for those who need to handle vast amounts of information. Given the current information overload era, users require more efficient tools to manage, understand, and digest information. The product currently offers a free trial, with specific pricing and positioning determined by user needs.
Efficiency Tools
99.1K
Fresh Picks
Omniaudio 2.6B
OmniAudio-2.6B is a multimodal model with 2.6 billion parameters that seamlessly processes both text and audio inputs. This model combines Gemma-2B, Whisper Turbo, and a custom projection module. Unlike the traditional method of chaining ASR and LLM models, it unifies both capabilities in an efficient architecture, achieving minimal latency and resource overhead. This enables it to securely and rapidly process audio-text directly on edge devices such as smartphones, laptops, and robots.
Speech Recognition
55.2K
Whisper Ner V1
Whisper-NER is an innovative model that allows for simultaneous speech transcription and entity recognition. This model supports open-type Named Entity Recognition (NER) and can identify a diverse and evolving set of entities. Whisper-NER is designed as a robust foundational model for automatic speech recognition (ASR) and NER downstream tasks and can be fine-tuned on specific datasets to enhance performance.
Entity Recognition
50.0K
Ultravox V0 4 1 Mistral Nemo
ultravox-v0_4_1-mistral-nemo is a multimodal speech large language model (LLM) based on pre-trained Mistral-Nemo-Instruct-2407 and whisper-large-v3-turbo. The model can handle both speech and text input simultaneously, such as a text system prompt and a speech user message. Ultravox converts input audio into embeddings using a special <|audio|> pseudo-token and generates output text. Future versions plan to expand the token vocabulary to support generating semantic and acoustic audio tokens, which can then be input into a vocoder to produce speech output. The model is developed by Fixie.ai and is licensed under MIT.
Speech Translation
50.2K
Ultravox V0 4 1 Llama 3 1 70b
fixie-ai/ultravox-v0_4_1-llama-3_1-70b is a large language model based on pre-trained Llama3.1-70B-Instruct and whisper-large-v3-turbo, capable of handling speech and text input to generate text output. The model converts input audio into embeddings using a special pseudo-tag <|audio|>, which are then merged with text prompts to generate output text. Ultravox is developed to expand the application scenarios of speech recognition and text generation, such as voice agents, speech-to-speech translation, and spoken audio analysis. The model is under the MIT license and developed by Fixie.ai.
Text Generation
49.1K
Ultravox V0 4 1 Llama 3 1 8b
fixie-ai/ultravox-v0_4_1-llama-3_1-8b is a large language model based on pre-trained Llama3.1-8B-Instruct and whisper-large-v3-turbo, capable of processing speech and text input to generate text output. The model converts input audio to embeddings using a special <|audio|> pseudo-token and generates output text. Future versions plan to expand the token vocabulary to support semantic and acoustic audio token generation, which can then be used by a vocoder to produce speech output. The model performs excellently in translation evaluation and has no preference adjustment, making it suitable for scenarios such as voice agents, speech-to-speech translation, and speech analysis.
Speech Translation
45.8K
Ultravox.ai
Ultravox.ai is an advanced Speech Language Model (SLM) that processes voice directly without converting it to text, enabling more natural and fluent conversations. It supports multiple languages and easily adapts to new languages or accents, ensuring smooth communication with diverse audiences. As an open-source model, Ultravox.ai allows users to customize and deploy according to their specific needs, priced at $0.05 per minute.
Natural Language Processing
114.3K
Kaka Subtitle Assistant
Kaka Subtitle Assistant (VideoCaptioner) is a powerful video subtitle creation software that utilizes large language models for intelligent segmentation, correction, optimization, and translation of subtitles, achieving one-click processing for the entire subtitle video workflow. The product requires no high-end configurations, is user-friendly, and comes with a built-in basic LLM model, ensuring it is ready to use right out of the box while consuming a minimal amount of model tokens, making it suitable for video producers and content creators.
Speech Recognition
110.4K
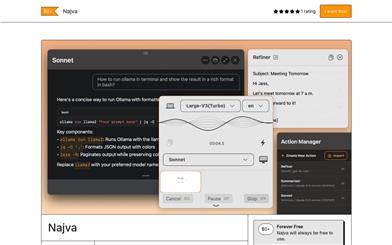
Najva
Najva is an AI-driven speech assistant designed specifically for Mac, combining advanced local speech recognition technology with powerful AI models to transform your speech into intelligent text. This application is particularly beneficial for users whose thought speed outpaces their typing speed, such as writers, developers, and healthcare professionals. With its lightweight design, native Swift application, zero tracking, and completely free access, Najva provides a privacy-focused and efficient workflow solution.
Personal Care
50.2K

Hertz Dev
Hertz-dev is a full-duplex, audio-only transformer foundational model open-sourced by Standard Intelligence, featuring 8.5 billion parameters. This model represents scalable cross-modal learning technology capable of converting mono 16kHz speech into an 8Hz latent representation at a bitrate of 1kbps, outperforming other audio encoders. Key advantages of hertz-dev include low latency, high efficiency, and accessibility for researchers to fine-tune and build upon. Contextual information indicates that Standard Intelligence is committed to developing general intelligence that benefits humanity, with hertz-dev being a substantial step in that direction.
Model Training and Deployment
52.4K
Transcribro
Transcribro is a private, on-device speech recognition keyboard and text service application for the Android platform. It utilizes whisper.cpp to run OpenAI's Whisper series model and integrates Silero VAD for voice activity detection. The app provides a speech input keyboard, allowing users to input text via speech, and can be explicitly used by other applications or set as the user's preferred speech-to-text app. Some applications may use it for speech-to-text conversion. Transcribro's foundation is to offer users a safer and more private speech-to-text solution, avoiding potential privacy breaches associated with cloud processing. The application is open source, enabling users to freely view, modify, and distribute the code.
Speech Recognition
59.9K
Universal 2
Universal-2 is the latest speech recognition model launched by AssemblyAI, surpassing the previous Universal-1 in both accuracy and precision. It captures the complexities of human language more effectively, providing users with audio data that requires no secondary verification. The significance of this technology lies in its ability to deliver sharper insights, faster workflows, and an exceptional product experience. Universal-2 features notable improvements in proper noun recognition, text formatting, and alphanumeric recognition, consequently reducing word error rates in practical applications.
Speech Recognition
51.1K
GLM 4 Voice
GLM-4-Voice is an end-to-end voice model developed by a team from Tsinghua University, capable of directly understanding and generating Chinese and English speech for real-time dialogue. Leveraging advanced speech recognition and synthesis technologies, it achieves seamless conversion from speech to text and back to speech, boasting low latency and high conversational intelligence. The model is optimized for intellectual engagement and expressive synthesis capabilities in the voice modality, making it suitable for scenarios requiring real-time voice interaction.
Speech Recognition
61.3K
Whispo
Whispo is a speech dictation tool that leverages artificial intelligence technology to convert users' speech into text in real-time. Utilizing OpenAI's Whisper technology for voice recognition, it supports custom API use for transcription and allows for post-processing with large language models. Whispo is compatible with various operating systems, including macOS (Apple Silicon) and Windows x64, and ensures user privacy by storing all data locally. It is designed to improve the efficiency of users who require significant text input, whether for programming, writing, or everyday note-taking. Whispo is currently available for free trial, although specific pricing strategies have not been clearly stated on the website.
Speech Recognition
50.2K

Spirit LM
Spirit LM is a fundamental multimodal language model that can freely combine text and speech. The model is based on a 7B pretrained text language model and extends to the speech modality through continuous training on both text and speech units. Speech and text sequences are concatenated into a single token stream and trained using a small automatically curated speech-text parallel corpus with a word-level interleaving approach. Spirit LM offers two versions: the basic version uses speech phoneme units (HuBERT), while the expressive version adds pitch and style units to simulate expressiveness. For both versions, text is encoded using subword BPE tokens. This model not only demonstrates the semantic capabilities of text models but also showcases the expressive abilities of speech models. Furthermore, we demonstrate that Spirit LM can learn new tasks across modalities with few samples (e.g., ASR, TTS, speech classification).
AI Model
48.6K
Funasr
FunASR is an offline voice file transcription software package that integrates speech endpoint detection, speech recognition, and punctuation models. It can convert long audio and video files into punctuated text while supporting concurrent transcription of multiple requests. The system supports ITN and user-defined keywords, and the server integrates ffmpeg, accommodating various audio and video format inputs. It offers clients in multiple programming languages, making it ideal for enterprises and developers needing efficient and accurate voice transcription services.
AI speech-to-text
61.5K
Asrtools
AsrTools is an AI-powered speech-to-text tool that utilizes major ASR service interfaces to provide efficient speech recognition without requiring GPU or complex configurations. This tool supports batch processing and multithreading, allowing rapid conversion of audio files into SRT or TXT subtitle files. The user interface of AsrTools, built with PyQt5 and qfluentwidgets, offers an attractive and easy-to-navigate experience. Key advantages include stable integration with major service interfaces, convenience without complex setups, and flexibility in output formats. AsrTools is ideal for users who need to quickly convert speech content into text, especially in fields like video production, audio editing, and subtitle generation. Currently, AsrTools offers a free usage model for major ASR services, significantly reducing costs and enhancing workflow efficiency for individuals and small teams.
AI speech to text
99.4K
English Picks
Notesgpt
NotesGPT is an online service that leverages artificial intelligence technology to transform users' voice notes into organized summaries and clear action items. Utilizing advanced speech recognition and natural language processing techniques, it helps users efficiently record and manage notes, particularly useful for those who need to quickly document information and organize it into structured content. Background information shows that NotesGPT is supported by technology from Together.ai and Convex, indicating a strong AI technology foundation. Currently, the product appears to be in a promotional phase, with specific pricing and positioning details not explicitly available on the page.
AI writing assistant
68.2K

Reverb
Reverb is an open-source inference codebase for speech recognition and speaker segmentation models, utilizing the WeNet framework for ASR and the Pyannote framework for speaker segmentation. It offers detailed model descriptions and allows users to download models from Hugging Face. Reverb aims to provide developers and researchers with high-quality tools for various speech processing tasks.
AI Speech Recognition
57.7K
- 1
- 2
- 3
- 4
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M